

QTest
QTest load test Web and Mobile applications
Accurate and comprehensive analysis of application production ensures better performance. Yet, due to the demands of Operational Departments and because of the technologies used, applications must often be implemented in very short lengths of time. They are, however, more and more complex as well as heterogeneous.
QTest lets you ensure that the performance provided by your business applications will meet your quality of service commitments.
QTest detects performance anomalies and gives you a diagnostics
Easy to use, Qtest integrates into the entire application development and quality control cycle. Operating anomalies are identified and analyzed to allow for immediate correction. Any bottlenecks are eliminated.
Qtest allows the testing of a range of project types, including those based on J2EE, .Net, SAP, Siebel, Webservices, as well as Web 2.0 projects using technologies such as Adobe Flash/Flex. Client/Server applications as well as Citrix-style remote display applications can similarly be stressed.
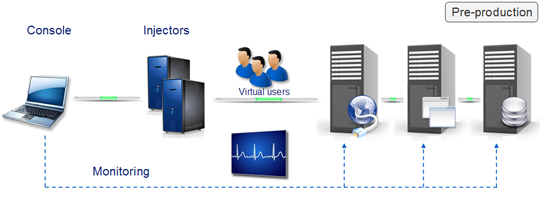
An enterprise solution, Qtest brings you the means to improve the performance of your critical applications thanks to:
A business-based approach in conducting your performance tests:
- Graphic viewing of business scenarios.
- Rapid understanding of tests with validation of your application SLAs.
- Monitoring the activity of every virtual user.
Simple to use means a high capacity to simulate load:
- Automatically detects the type of application.
- Browses the script by storyboard.
- Advanced assistants for parameter setting.
- Simulates tens of thousands of users.
Automatically detecting and analyzing anomalies:
- Full hardware and software infrastructure monitoring thanks to a series of non-intrusive performance monitors.
- A real-time analysis of entire metrics.
- Breaks down response times for clients, network and servers.
- Summarizes relevant metrics for operating systems, application servers, web servers and databases.
Automatic report creation:
- Produces sophisticated reports based on standard or customized models suited to your business needs.
- Reports for monitoring your SLA quality of service commitments.
- Reports for each user profile.
- Compares execution results.
Support for all environments:
- Web Service, J2EE, .Net, ASP, CGI, Mainframe Portal, Web 2.0 such as Adobe Flash/Flex, Microsoft Silverlight, Html/Ajax, Microsoft Sharepoint
- With the Winload module, Qtest allows you to extend your load tests to all Windows client/server and ERP applications especially SAP Major Clients, PeopleSoft, Oracle, Citrix
- Thanks to its QNI module, Qtest can adapt to specific environments.
Technologies supported
RIA, AJAX, Air&Flex, Silverlight, Sharepoint, JSON
DotNet, J2EE, PHP, ASP, Webservices, SOAP
Siebel Web, SAP Web, Oracle e-business, PeopleSoft, JD Edwards, HRAccess, Hyperion
Citrix, TSE, Client-Server, TCP
etc.
Platforms
OS : Windows, Unix, Linux, VMWare ESX
Serveur Web : IIS, Apache
Application Servers : .Net, JBoss, Tomcat, Websphere, Weblogic, OracleAS
Databases : Oracle, SQL Server, Sybase, MySQL, Informix, PostgreSQL, DB2
AgileLoad is a new and flexible way use QTest to test the performance of web and mobile applications. Performance test scenarios can be built, customized and tested without paying a fee. You pay on-demand for large test runs for the load and timeframe you decide upon.
AgileLoad runs equally on the cloud or on site. With a single license, you can generate load from your network initially and then on the cloud for complete test coverage.
A small company could easily become a cloud service provider utilizing AgileLoad running on Amazon EC2. Online tutorials, Online license management, no extra cost for cloud testing, no extra cost for specific protocols or monitoring, everything is included in one package : simple and easy!
Setting up an Amazon EC2 Virtual Machine as an Injector
Performance / load testing from the cloud has many benefits. Cloud load and performance testing enables low cost execution of very large tests without having to invest in large infrastructures by using Amazons redundant data centres. Furthermore cloud based load and performance testing allows load generation from around the world to simulate users in other countries thereby testing the entire end to end infrastructure including your gateways, load balancers and the internet. An understanding can be gained of end user experience and contracting between local and very remote users will show the sum total of the effects of jitter, latency and bandwidth issues.
Mobile Performance & Load Testing (Transaction Script Capture)
Capturing user activity from a device is easy with AgileLoad due to the multiple capture mechansims it supports. In this case we capture a few mobile web requests from an iPhone which could then be used to build a mobile testing scenario. Once the transaction is captured in AgileLoad it is edited in the same way that any other kind of script is edited in AgileLoad.
Script Parameterisation 1: Capturing the Script in Script Editor
How to record a script in AgileLoad script editor. This script is evolved over the next three videos into a parametrised, data driven script.
Script Parameterisation 2: Usernames – Making a Script Data Driven
To create realistic load test you need realistic scenarios and scripts to underpin them. One vital point is to be able to make your test scripts data driven. In this video we show you how to use the data generated in the data generation script to ensure that users in teh test each log on as a unique user from a list of 1000 possible credentials
Script Parameterisation 3: Choosing a Random Link
In this final stage we see how to make the AgileLoad script choose a random link (hence random product) from the list of products available. So to summarise the script will see a virtual user log in as a random user chosen from a list of 1000 possible user names, it will then choose a random product from the products page and buy that same random product.
Automatic Script Parametrisation Setup
Here we go through how to set up automatic script parameterisation using AgileLoads models. Very useful to save hours, days or weeks on load test projects where scriptijng is repetetive and taking a lot of project time. This video shows you how to teach AgileLoad how to autoamtically parameterise comlplicated scripts, in this case we use a customised sharepoint applciaiton as an example.
Manual Script Parameterisation
Load test creation : This video shows step by step how to parameterise a value in a script
AgileLoad Script Editing: Add Transaction Loop Boundaries
Two part video that shows how to simulate a scenario where a user goes to a home page and then loops around the product pages of a site, could also be useful to simulate a scenario where a user logs in once, executes some transaction n times and log out once. Part 1: Describing how to add transaction loop boundaries to scripts Part 2: Using that script to execute a small test against the target web site The video demonstrates the use of TransactionBegin and TransactionEnd to control the execution of the requests in the script.
Test Data Generation with Agile Load
Load and Performance testing can require huge amounts of data from login credentials to user accounts. Generating this data is not possible manually because of the sheer volumes required. In this video we create some user accounts on our target web application so that we can later use those accounts to log on with for our load test. The data is generated from scratch using AgileLoad’s data generation tool.
Text Execution and Monitoring
Research Center
- Best load testing tools – the right features mix
- Most notable web application performance failures – a top 5 list
- Risks of Testing Performance in Scaled down environments
- A transition from Loadrunner to QTest
- ‘Monitoring’ a key partner of ‘Testing’
- Basic mathematics for performance testers
- Load testing – Calculating the pacing time
- AGILE & Performance testing